Banco de dados de 1 Terabyte
Data da última atualização: 24/08/2009
Porque criar um banco de dados de um terabyte com o Firebird?
Muitas companhias trabalham com grandes bases de dados no Firebird e confiam nelas para realizar importantes operações de negócio. Algumas dessas bases de dados já têm centenas de gigabytes de tamanho, e continuam a crescer (leia mais na seção “quem é grande?”), e não é difícil de prever o dia em que serão 2, 3 ou 5 vezes maiores. Sendo assim, é interessante para os administradores saberem qual o comportamento do Firebird com bases de dados grandes, e obter algumas recomendações de como administrá-las.
Uma outra razão importante que tínhamos em mente ao criar uma base de 1Tb é acabar de uma vez por todas com a idéia de que o Firebird é um SGBD para pequenas bases de dados. Esse mito parecia estar morto, mas alguns analistas e jornalistas desenterram-no de tempos em tempos, sendo que agora, pretendemos acabar de uma vez por todas com essa percepção ridícula.
Hardware
O Firebird é bem conhecido por sua incrível escalabilidade, e nossos testes confirmam isso mais uma vez. O propósito inicial deste teste era apenas criar um banco de dados de 1Tb, portanto, usamos um computador desktop normal:
Tabela 1: Hardware usado
Componente |
Parâmetros |
CPU |
AMD Athlon 64 x2 5200 |
RAM |
4GB |
Motherboard |
MSI K9N Platinum |
HDD1 (operation system and temp) |
ST3160815AS, 160GB, SATA II |
HDD2 (auxilary) |
HDT721064SLA360, 640GB, SATA II |
HDD2 (auxilary) |
HDS728080PLA380, 80GB, SATA I |
HDD3 (database) |
ST31500341AS, 1.5TB, SATA II (Firmware CC1H) |
Resumindo, colocamos um HD de 1.5Tb em um dos nossos computadores, sem qualquer modificação. Esse HD foi formatado com clusters de 16Kb (o mesmo tamanho de uma página do banco de dados).
Quem é grande?Existem diversas empresas que gerenciam bases de dados Firebird significativamente grandes. A seguir, listamos três delas como exemplos de uso real de grandes bases de dados Firebird em empresas de três áreas distintas: varejo, finanças e medicina. |
Bas-XBas-X (http://www.basx.com.au/, Australia) é líder no fornecimento de tecnologia de informação para varejistas, particularmente operadores “multi-site” e grupos de gerência. Bas-X é um grande exemplo na tecnologia do Firebird: dois dos seus clientes tem bases de dados Firebird com mais de 450GB, e diversos outros possuem bases de mais de 200Gb. |
Watermark TechnologiesWatermark Technologies (http://www.watermarktech.co.uk/, UK) é um ótimo exemplo de uso do Firebird para servir empresas nas áreas de Finanças e setores Governamentais. |
ProfitmedProfitmed (http://www.profitmed.net/, Rússia), um dos maiores distribuidores farmacêuticos da Rússia. Eles possuem bancos de dados relativamente pequenos (somente 40Gb), mas decidimos citá-los pelo fato de terem uma alta carga de conexões simultâneas, servindo milhares de pequenas revendas e farmácias em toda a Rússia. Apesar dos tamanhos dos bancos de dados serem menores do que os já apresentamos, eles contém dados de alta densidade: SKUs de medicamentos, movimentação de armazenagem representados em números, e graças ao mecanismo de compressão de dados do Firebird, essas informações ocupam pouco espaço em disco. |
Software
Como o computador usado era uma micro normal de trabalho, o sistema operacional foi o Windows XP Professional SP3, 32bit. Para realizar o teste, foi usado o loader baseado no toolkit do TPC (baixe-o em http://ibdeveloper.com/tests/tpc-c/, tanto o fonte como os binários estão disponíveis).
Gostaríamos de enfatizar que o loader insere dados simulando uma situação de uso real: os registros são inseridos e armazenados dentro do BD (e das áreas físicas do disco) em diversas tabelas seguindo o relacionamento mestre-detalhe, e não inseridos de forma seqüencial, tabela por tabela (pump).
Tabela 2: Software
Software |
Versão |
Sistema Operacional |
Windows XP Professional SP3, 32bit |
Firebird |
2.1.3 SuperServer (snapshot) |
Loader |
Custom loader from tpc-based test |
Plan
Nosso plano de testes era muito simples:
- Criar um BD e carregar ele com 1Tb de dados, sem índices
- Criar diversas chaves primárias e índices (portanto, o tamanho do banco é um pouco maior que 1Tb)
- Colher estatística do BD
- Rodar diversas queries de SQL e estimar a performance do BD
Configuração do banco de dados e do Firebird
O BD usa páginas de 16384 bytes, o mesmo tamanho do cluster do HD, a fim de maximizar a performance das operações de leitura/escrita em uma página por ciclo de I/O.
Na configuração do Firebird, configuramos espaço adicional para os dados temporários, apontando o espaço do temp para um HD de 640GB (com aproximadamente 300Gb livres).
Processo de carregamento
Os dados foram carregados no BD em várias etapas. O computador continuou sendo utilizado para outras tarefas durante o processo (MS Office, Firefox, IBAnalyst, etc – entre 8 e 12 programas rodando ao mesmo tempo). Usando um hardware dedicado para esta tarefa, provavelmente ela seria mais rápida, portanto, considere os valores como um exemplo de “pior caso”; definitivamente, poderíamos obter valores muito melhores.
Tabela 3: Operações de carregamento
Descrição |
Valor |
Tempo total de carregamento |
~70 horas |
Total de registros inseridos |
6.2 bilhões |
Velocidade media de inserção |
24.500 registros/segundo |
Tamanho médio de um registro |
146 bytes (min 13 bytes, max – 600 bytes) |
Transações |
646.489 |
Foi gasto quase 4 dias para carregar o banco, chegando a um BD com exatamente 1Tb de tamanho (1.099.900.125.184 bytes). Abaixo você pode verificar o gráfico gerado pelo FB DataGuard que demonstra o crescimento do BD e o número de transações dinâmicas:
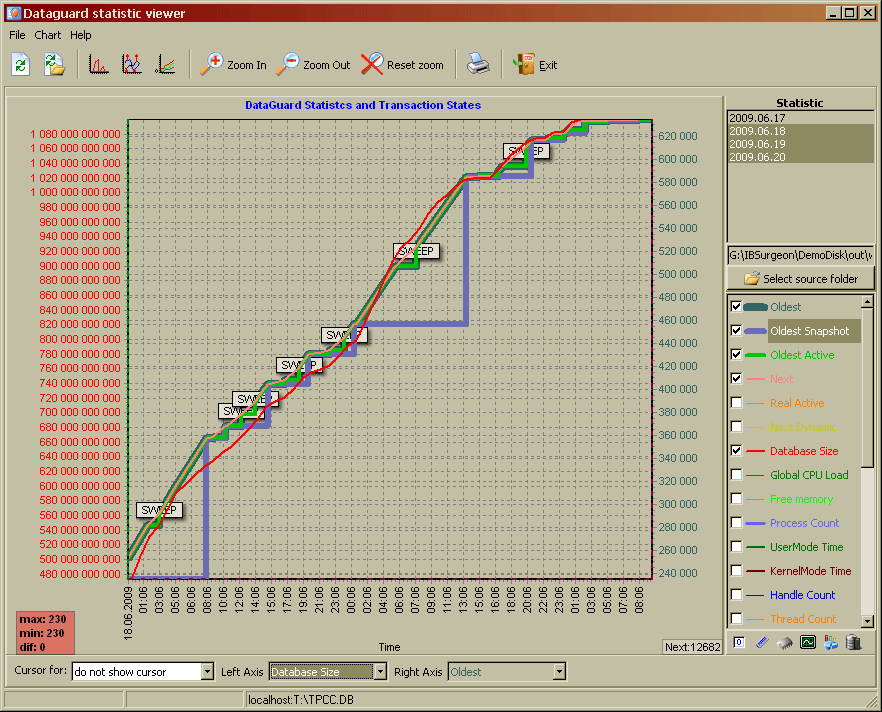
Índices
Criamos os índices um por um, e contamos o tempo de criação e tamanho do arquivo temporário utilizado para ordenação.
O maior índice foi criado na tabela ORDER_LINE. Sua chave primária é composta por 4 campos (Smallint, Smallint, Integer and Smallint). O arquivo temporário para a indexação ocupou 182Gb, e o tamanho final do índice ficou em 29.3Gb.
Foi interessante observar que mesmo em um índice para uma tabela com 3.8 blhões de registros, a profundidade foi igual a 3, devido ao tamanho da página ser de 16Kb, portanto, não há sobrecarga ao realizar pesquisas na chave primária para esta tabela.
Estatísticas
Depois do processo de criação dos índices, era hora de colher as estatísticas do BD. Esta etapa demorou 7 horas, 32 mins e 45 seg. A tabela 4 mostra as estatísticas mais interessantes, incluindo algumas queries e tempos.
Tabela 4: Estatísticas consolidadas para o BD de 1Tb
Tabela |
Total de registros |
Tamanho (Gb) |
Tempo de execução de um select count(*) |
Tempo de criação de índice |
Tamanho do arquivo temporário (Gb) |
Tamanho do índice (Gb) |
WAREHOUSE |
1240 |
0.002 |
0s |
0 |
0 |
0.0 |
ITEM |
100000 |
0.012 |
0.7s |
- |
- |
0.0 |
DISTRICT |
124000 |
0.017 |
0.7s |
6 |
- |
0.0 |
NEW_ORDER |
111600000 |
32 |
20m 00s |
23m 00s |
4.56 |
0.8 |
CUSTOMER |
372000000 |
224 |
- |
41m 00s |
- |
2.6 |
customer_last |
|
|
|
1h 52m 32s |
12.4 |
2.3 |
fk_cust_ware |
|
|
|
2h 10m 51s |
- |
2.3 |
HISTORY |
372000000 |
32 |
- |
- |
- |
- |
ORDERS |
372000000 |
25 |
32m 00s |
45m 41s |
15.2 |
2.5 |
STOCK |
1240000000 |
404 |
- |
3h 34m 44s |
41.5 |
9.2 |
ORDER_LINE |
3720051796 |
359 |
- |
12h 6m 18s |
182.0 |
29.3 |
As estatísticas podem ser baixadas em http://www.ib-aid.com/demo/1tb.zip
Você pode usar o FB DataGuard Community Edition (gratuito) para interpretar os dados não só da performance do BD, mas também do uso de memória e CPU.
Queries
Antes de qualquer coisa, foi executado um select count(*) em diversas tabelas (conforme a tabela 4). Como você deve saber, devido à natureza de múltiplas versões utilizada no Firebird, executar um select count(*) para um tabela completa é uma operação bastante custosa para o servidor, pois faz com que ele acesse todas as páginas, portanto, usuários experientes do FB não costumam fazer isso, mas resolvemos fazer isso para mostrar a performance geral do BD e do hardware.
Em seguida, executamos queries usadas em situações da vida real, e ficamos maravilhados com o resultado. Veja você mesmo:
Query |
Statistics |
Description |
select w_id, w_name, c_id, c_last |
PLAN JOIN (WAREHOUSE NATURAL, CUSTOMER INDEX (FK_CUST_WARE)) ------ Performance info ------ |
Junção de tabelas com 12.400 e 372.000.000 registros, sem cláusula WHERE. O tempo mostrado é para recuperar a primeira linha. |
select w_id, w_name, c_id, c_last |
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE)) ------ Performance info ------ |
Join das mesmas tabelas acima, mas usando uma condição para restringir os registros mais atuais. O tempo mostrado é para recuperar a primeira linha. |
select count(*) Result = 30000 |
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE)) ------ Performance info ------ |
Contagem dos registros do select anterior. |
|
|
|
SELECT * FROM ORDER_LINE
|
Plan ------ Performance info ------ |
Query na maior tabela do BD (3.8 bilhões de registros). O tempo mostrado é para recuperar a primeira linha. |
|
|
|
|
PlanPLAN (ORDER_LINE INDEX (ORDER_LINE_PK)) ------ Performance info ------Prepare time = 0msExecute time = 3s 438msAvg fetch time = 0.01 msCurrent memory = 136 445 496Max memory = 136 592 176Memory buffers = 8 192Reads from disk to cache = 1 840Writes from cache to disk = 0Fetches from cache = 598 636
|
|
SELECT * FROM ORDER_LINE
|
Query na maior tabela (3.8 bilhões de registros), recuperando todos os registros resultantes (299.245 registros foram recuperados). |
|
|
|
Sumário
Neste experimento, o Firebird mostra os seguintes resultados:
- Capacidade indiscutível de gerenciar bases de dados realmente grandes. Estamos certos de que é possível criar e usar bases de 32Tb com o hardware apropriado, mantendo a performance obtida em BDs menores.
- Boa escalabilidade e pequeno footprint. O BD de 1Tb foi criado em uma máquina de uso geral (desktop) e, mais importante, pode ser usado para executar queries normais: se você não selecionar milhões de registros com a query, a performance será a mesma obtida em BDs menores (10-15Gb).
Este não é o fim deste experimento. Ainda pretendemos rodar outras queries, colher mais estatísticas e publicar reports mais detalhados em breve.
Contatos
Envie todas as suas dúvidas para terabyte@ib-aid.com
Tradução/adaptação: Carlos H. Cantu (www.firebase.com.br)
Copyright (C) Carlos H. Cantu - É proibida a reprodução de qualquer material desse site sem autorização prévia